language en
The AI Method Evaluation Ontology
- Latest version:
- https://www.w3id.org/iSeeOnto/aimethodevaluation
- Contributors:
- Anjana Wijekoon
- Chamath Palihawadana
- David Corsar
- Ikechukwu Nkisi-Orji
- Juan A. Recio-Garcia
- Marta Caro Martínez
- Imported Ontologies:
- explanationPattern.owl
- sio.owl
- cpannotationschema.owl
- prov-o#
- aimodel
- eo
- Download serialization:

- License:

- License:
- Visualization:

- Cite as:
- The AI Method Evaluation Ontology.
Ontology Specification Draft
Abstract
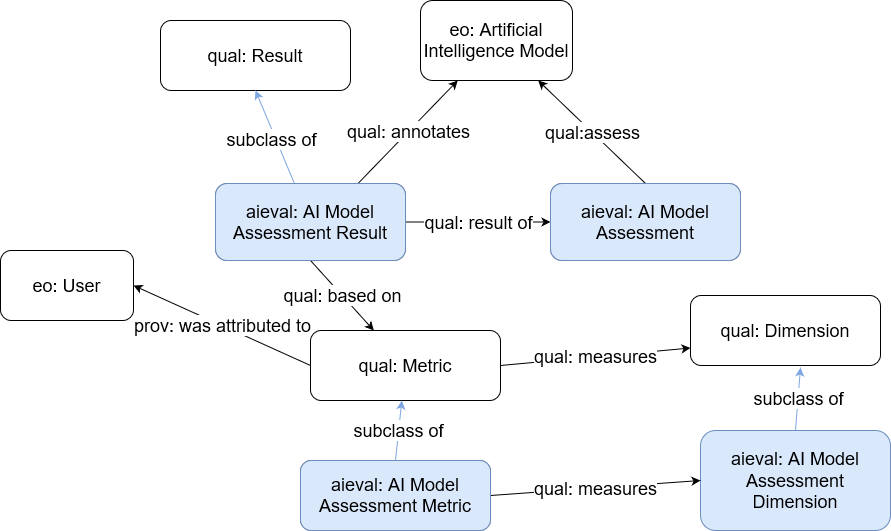
The AI Method Evaluation Ontology is an ontology that models the assessments, such as accuracy, F1 score, etc. of an AI Method. An assessment activity is performed to evaluate the performance of a AI Method, using a metric which defines how the assessment should be performed. The outcome of the assessment is captured in the Result concept. The metric measuress some aspect of the AI Method, such as accuracy, precision, recall, completeness, etc. The assessment is performed by an Agent, either software or human. The Prov properties startedAtTime and endedAtTime are used to record when the assessment took place. This pattern is based on that of Qual-O defined in C. Baillie, P. Edwards, and E. Pignotti, 2015. QUAL: A Provenance-Aware Quality Model. J. Data and Information Quality 5, 3, Article 12 (February 2015) DOI:https://doi.org/10.1145/2700413. This ontology was created as part of the iSee project (https://isee4xai.com) which received funding from EPSRC under the grant number EP/V061755/1. iSee is part of the CHIST-ERA pathfinder programme for European coordinated research on future and emerging information and communication technologies.Introduction back to ToC
Namespace declarations
| aieval | <https://www.w3id.org/iSeeOnto/aimethodevaluation> |
| schema | <http://schema.org> |
| owl | <http://www.w3.org/2002/07/owl> |
| Fowlkes | <http://www.w3id.org/iSeeOnto/aimodelevaluationFowlkes–> |
| xsd | <http://www.w3.org/2001/XMLSchema> |
| skos | <http://www.w3.org/2004/02/skos/core> |
| rdfs | <http://www.w3.org/2000/01/rdf-schema> |
| cito | <http://purl.org/spar/cito> |
| prov-o | <http://www.w3.org/TR/prov-o> |
| terms | <http://purl.org/dc/terms> |
| xml | <http://www.w3.org/XML/1998/namespace> |
| vann | <http://purl.org/vocab/vann> |
| Youden | <http://www.w3id.org/iSeeOnto/aimodelevaluationYouden'> |
| aimodel | <http://www.w3id.org/iSeeOnto/aimodel> |
| prov | <http://www.w3.org/ns/prov> |
| foaf | <http://xmlns.com/foaf/0.1> |
| void | <http://rdfs.org/ns/void> |
| resource | <http://semanticscience.org/resource> |
| Qual-O | <http://sensornet.abdn.ac.uk/onts/Qual-O> |
| protege | <http://protege.stanford.edu/plugins/owl/protege> |
| cpannotationschema | <http://www.ontologydesignpatterns.org/schemas/cpannotationschema.owl> |
| eo | <https://purl.org/heals/eo> |
| core | <http://purl.org/vocab/frbr/core> |
| rdf | <http://www.w3.org/1999/02/22-rdf-syntax-ns> |
| aieval | <http://www.w3id.org/iSeeOnto/aimodelevaluation> |
| obo | <http://purl.obolibrary.org/obo> |
| dc | <http://purl.org/dc/elements/1.1> |
The AI Method Evaluation Ontology: Overview back to ToC
This ontology has the following classes and properties.Classes
- AI Model Assessment
- AI Model Assessment Dimension
- AI Model Assessment Metric
- AI Model Assessment Result
Named Individuals
- Accuracy
- Adjusted Rand Index
- AU-ROC
- BLEU
- Brier Score
- Calinski-Harabasz Index
- Cohen's Kappa Coefficient
- Coverage
- Data Quality
- Davies-Bouldin Index
- Dice Index
- Discounted cumulative gain
- Diversity
- Dunn Index
- F1-score (macro)
- F1-score (micro)
- Fowlkes–Mallows index
- Hamming Loss
- Hopkins statistic
- Inference Speed
- Jaccard Score
- Mathews Correlation Coefficient
- Mean Absolute Error
- Mean Squared Error
- METEOR
- Mutual Information
- Network Usage
- NIST
- Performance
- Perplexity
- Precision
- Purity
- R squared
- Rand Index
- Recall
- Recommender persistence
- Robustness
- Root Mean Squared Error
- ROUGE
- Serendipity
- Silhouette Score
- Speed
- Stability
- Training Speed
- True Negative Rate
- WER
- Youden's J statistic
The AI Method Evaluation Ontology: Description back to ToC